Self-Rewarding Language Model
It’s been some time since my last post here. The world of AI doesn’t seem to slow down, and it’s always full of new things. It’s amazing how quickly things change; sometimes, missing a day or two of updates on Twitter (should be X, my primary source of research news) can make me feel a bit out of the loop. The challenge these days is not just keeping up, but choosing wisely what to delve into amidst the constant stream of new information. This year, I’m setting a goal to focus more on what really matters, instead of trying to catch every bit of news.
That said, when you come across a piece of research that’s making waves, claiming to outdo something as significant as GPT-4 (GPT-4 0613 to be exact), it definitely deserves attention. So, we will dicuss about Self-Rewarding Language Model, a recent work by Meta AI and NYU on a new fine-tuning methodology.
Background
Supervised fine-tuning (SFT)
It involves refining a pre-trained LLM using a specific dataset, allowing the model to become more adept in certain tasks or knowledge areas. It is similar causal language modelling we used during pretraining. The difference is that we required a supervised dataset (eg, dataset with instruction, question and answer / instruction and answer) and fine-tune the LLM to generate response similar to the answer in the datasets.
Direct Preference Optimization (DPO)
Even with Supervised Fine-Tuning (SFT), sometimes the output from our models can be unsatisfactory. They might include elements like toxicity, bias, or simply responses that don’t align with human preferences. This indicates that SFT alone might not be enough, as the models may not fully grasp the “standard answers” they should be producing. This is where DPO becomes vital. By implementing DPO, we can further enhance the performance of LLMs. DPO works by training the LLM on a dataset that includes instructions along with examples of both preferred and rejected responses. This method enables us to guide the LLM towards generating answers that align more closely with our preferences.
Specifically, DPO involves two models: the trained model (or policy model) and a reference model, which is essentially a copy of the original model with its weights frozen throughout the training process. The objective during DPO training is to adjust the trained model so that it assigns higher probabilities to preferred responses compared to the reference model. Conversely, for rejected responses, the goal is to ensure that these are less likely to be generated by the trained model than by the reference model. In essence, when a response is preferred, we aim to increase its generation probability in the policy model as much as possible, ensuring it surpasses the probability assigned by the reference model. Similarly, for a rejected response, we aim to minimize its generation probability in the policy model, even lower than that of the reference model.
Note: It’s important to recognize that DPO is a subset of Reinforcement Learning From Human Feedback (RLHF), with the key distinction being that it does not require a separate reward model during the training process.
Self-Rewarding Language Model
While DPO has shown potential in enhancing the abilities of LLMs, the process of acquiring human-annotated data in the required format is both challenging and costly. Additionally, relying solely on human judgment may not be sufficient in our pursuit to develop superhuman agents, which are expected to surpass human intelligence. Traditional RRLHF methods, such as Proximal Policy Optimization (PPO), also have limitations, primarily because they utilize a fixed-weight reward model that does not improve concurrently with the LLM during fine-tuning. This paper introduces a novel fine-tuning paradigm that enables the LLM to simultaneously enhance its instruction-following and reward-modelling abilities, rather than separating these functions into two distinct models.
The concept of self-rewarding fine-tuning is straightforward and involves the following steps:
- Begin with a pre-trained model and perform Supervised Fine-Tuning (SFT) using a dataset designed for instruction-following tasks, which may also include judgment tasks.
- Select some prompts from the original SFT dataset and create new variations of these prompts.
- For each new prompt variant, generate $N$ candidate responses.
- Utilize the same model to evaluate these responses, applying an LLM-as-a-Judge approach. This step creates a set of internally annotated data, eliminating the reliance on external human annotation.
- Use this internally generated evaluation data to further fine-tune the model using DPO.
- Repeat this process iteratively until there is no further improvement in the model’s performance, indicating a plateau.
Let’s discuss each step in details.
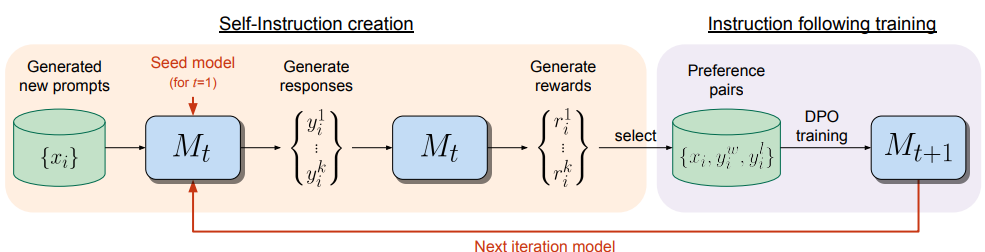
Step 1 Initialization: Start with a pre-trained model and an SFT dataset, which includes tasks that focus on following instructions as well as evaluation tasks. It’s worth noting that evaluation tasks are essentially a subset of instruction-following tasks, as they train the model to learn judging abilities. This initial step involves fine-tuning the model using the SFT approach with the provided dataset.
Step 2 Prompt generation: Following the SFT training, the researchers use a fixed model – Llama 2-Chat 70B with 8-shot prompting – to generate variant ($x_i$) of prompts sampled from the original SFT dataset. The choice of not using the fine-tuned model for this task might raise questions, but it could be tied to maintaining a consistent baseline for prompt generation.
Step 3 Candidate response generation: For each generated prompt, the fine-tuned model is used to create N = 4 ($y_i$) response. These responses are generated with a specified temperature of 0.7 and a top-p probability ($p$) of 0.9. This step aims to produce diverse and plausible responses for each prompt variant.
Step 4 DPO dataset generation: The fine-tuned model is then employed multiple times to evaluate these responses, with the average of these evaluations taken. Since the DPO training requires a dataset that includes instructions, along with positive and negative (winning and losing) responses, the highest and lowest average scoring responses from the $N$ evaluated candidates are selected. In cases where scores are identical, those pairs are discarded. It’s crucial to incorporate Chain-of-Thought reasoning in the prompts during this phase to enhance the reliability of the evaluation scores. The prompt used are shown as below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
"""Review the user’s question and the corresponding response using the additive 5-point
scoring system described below. Points are accumulated based on the satisfaction of each
criterion:
- Add 1 point if the response is relevant and provides some information related to
the user’s inquiry, even if it is incomplete or contains some irrelevant content.
- Add another point if the response addresses a substantial portion of the user’s question,
but does not completely resolve the query or provide a direct answer.
- Award a third point if the response answers the basic elements of the user’s question in a
useful way, regardless of whether it seems to have been written by an AI Assistant or if it
has elements typically found in blogs or search results.
- Grant a fourth point if the response is clearly written from an AI Assistant’s perspective,
addressing the user’s question directly and comprehensively, and is well-organized and
helpful, even if there is slight room for improvement in clarity, conciseness or focus.
- Bestow a fifth point for a response that is impeccably tailored to the user’s question
by an AI Assistant, without extraneous information, reflecting expert knowledge, and
demonstrating a high-quality, engaging, and insightful answer.
User: <INSTRUCTION_HERE>
<response><RESPONSE_HERE></response>
After examining the user’s instruction and the response:
- Briefly justify your total score, up to 100 words.
- Conclude with the score using the format: “Score: <total points>”
Remember to assess from the AI Assistant perspective, utilizing web search knowledge as
necessary. To evaluate the response in alignment with this additive scoring model, we’ll
systematically attribute points based on the outlined criteria."""
Step 5 & 6: After we obtain the dataset required for DPO, we can use it to further fine-tune the model using DPO. The process are repeat iteratively.
Note: The researchers also experimented with using the generated prompt variants and responses for additional SFT. However, they found that this approach did not yield as effective results as DPO fine-tuning.
Training details
For SFT:
Learning rate: 5.5e−6 which linearly decays to 1.1e−6,
Batch size: 16,
Dropout: 0.1,
Only calculate the loss on target tokens instead of the full sequence.
For DPO:
Learning rate: 1e−6 which linearly decays to 1e−7,
Batch size: 16,
Dropout: 0.1,
β value: 0.1.
Perform early stopping by saving a checkpoint every 200 steps.
Results
Instruction following results
The evaluation of the model’s instruction-following abilities was primarily conducted using GPT-4 as a benchmark. To assess the effectiveness of each iteration of the fine-tuning process, the researchers carried out a comparative analysis. This involved evaluating the performance of the model at each iteration against the original baseline model, as well as comparing each iteration’s performance against the preceding one. Such a methodical approach allowed for a detailed understanding of the incremental improvements and the overall efficacy of the fine-tuning process at each stage. The results of this evaluation are as follows:
 In their analysis, the researchers implemented a pairwise comparison method for evaluating the responses generated by the model. This approach involved presenting the responses in both orders to GPT-4, ensuring a thorough and unbiased evaluation. By switching the order of the responses, they could test for consistency in GPT-4’s assessment. If the evaluation results varied when the order of the responses was reversed, such instances were classified as a TIE.
In their analysis, the researchers implemented a pairwise comparison method for evaluating the responses generated by the model. This approach involved presenting the responses in both orders to GPT-4, ensuring a thorough and unbiased evaluation. By switching the order of the responses, they could test for consistency in GPT-4’s assessment. If the evaluation results varied when the order of the responses was reversed, such instances were classified as a TIE.
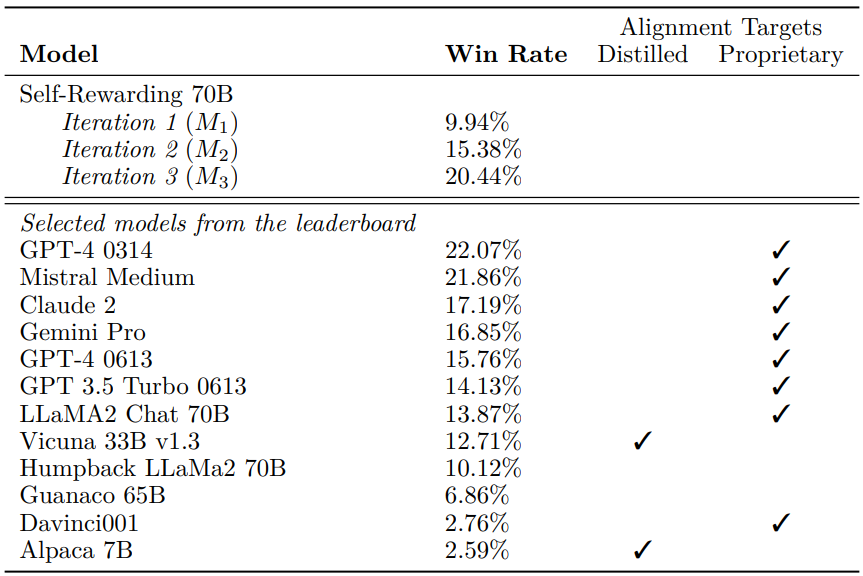
The following is the result from AlpacaEval 2.0 showing the self-rewarding (Llama-70b) is having similar performance with GPT-4 0314 and outperform GPT-4 0613.
Rewards modeling result
The evaluation on reward modeling is conducted on an evaluation set.
It mainly contains the following emtrics:
Pairwise accuracy: How many times the order of the ranking between any given pair agrees between the model’s evaluation and the human ranking.
Exact match: How often the total ordering is exactly the same for an instruction.
5-best: How often the responses
that the model scores a perfect 5 out of 5 are rated as the highest ranked by humans.
And also the Spearman correlation and Kendall’s τ.

Conclusion
While the findings of this study rely heavily on AlpacaEval for evaluating the LLM, this benchmark, though not perfect, offers valuable insights. This study unified fine-tuning approach, which enhances both instruction-following and reward modeling tasks, presents intriguing possibilities for the future of LLM development. It could opens to a lot of possibilities, like what if we further fine-tuning it with more iterations combined with SFT, using other approach like KTO, IPO etc, or even combined it with GAN-liked training mechanism SPIN, fine-tune other models with different order of magnitude etc. Also, it seems like it is possible to have open source LLMs to generate synthetic dataset could rival GPT-4 in terms of quality.
References
Paper: