What is text-to-image model personalization?
In a world where memories are precious and photos hold cherished moments, there are times when we yearn for more. Imagine having the power to bring your loved ones back to life, not just through existing photographs, but by recreating them in entirely new scenes. It’s now possible with the exponential grow of AI. With just a handful of example images, we can unlock the ability to recreate our loved ones, beloved characters, or cherished items in completely different contexts. That’s what text-to-image-model personalization is about. To be more precise, this remarkable technology has been introduced recently (less than one year?), which, ironically, makes it seem somewhat outdated given the rapid pace at which the field of AI is advancing.
Problem with existing text-to-image model personalization
However, while text-to-image model personalization has made impressive strides, it still faces limitations in its current state. Previous methods have primarily concentrated on learning a single concept from multiple images, (For example, given multiple image of a person, train the model to recreate them in different scene) which often vary in backgrounds and poses. Unfortunately, these methods encounter difficulties when applied to diverse scenarios or when attempting to incorporate multiple concepts simultaneously.
 Consider the following scenario: an image featuring two distinct subjects represented by [𝑣1] and [𝑣2]. Existing methods, like Textual Inversion (TI) [1] and DreamBooth (DB) [2], face significant challenges when attempting to generate an image that faithfully aligns with the provided prompt, “A photo of [𝑣1] and [𝑣2] on the beach.” This problem arises due to an inherent tradeoff between reconstruction and editability in these methods.
Consider the following scenario: an image featuring two distinct subjects represented by [𝑣1] and [𝑣2]. Existing methods, like Textual Inversion (TI) [1] and DreamBooth (DB) [2], face significant challenges when attempting to generate an image that faithfully aligns with the provided prompt, “A photo of [𝑣1] and [𝑣2] on the beach.” This problem arises due to an inherent tradeoff between reconstruction and editability in these methods.
When using TI (depicted on the left), it struggles to maintain the subject identities while managing to match the “on the beach” prompt. On the other hand, DB (shown in the middle) excels at preserving identity but fails to position the subjects on a beach. Evidently, optimizing individual tokens alone, as in TI, proves insufficient for achieving high-quality reconstruction. Conversely, fine-tuning the model using a single image, as in DB, increases the risk of overfitting, leading to suboptimal results.
This paper aims to strike a harmonious balance between these two approaches, combining the strengths of both to achieve superior results.
Additional information: Given few personalized image, TI freeze the pretrained latent diffusion model weights and only focus on training the text encoder such that it can map the concept in the image to a word embeddings that can be injected into prompt embeddings to generated the concept in a desired context.
Methodology
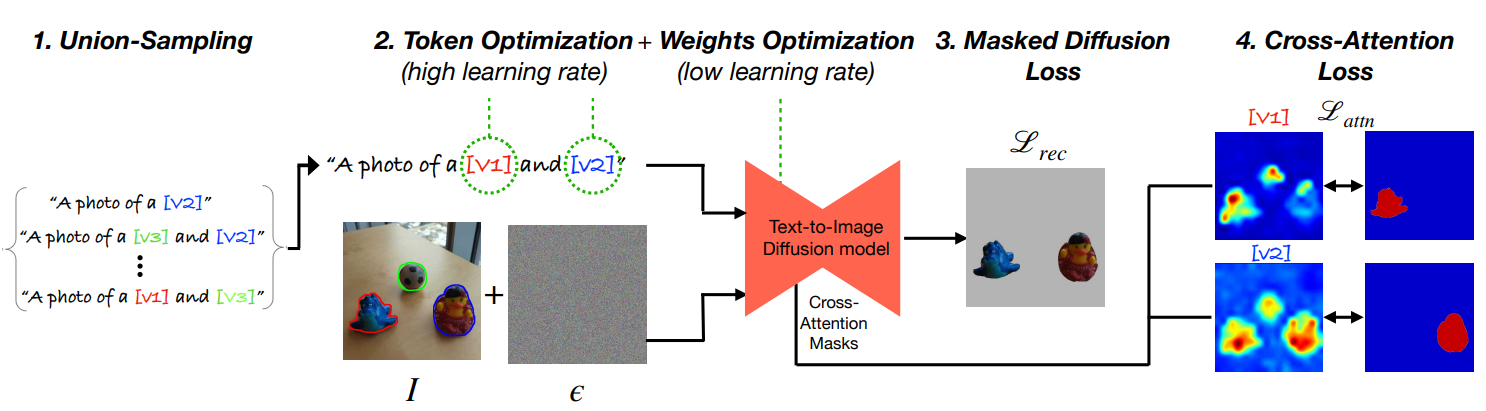 As mentioned earlier, this paper aims to combine the best of both worlds. To accomplish this, they employ a two-phase training approach that optimizes both the text embeddings and model weights.
As mentioned earlier, this paper aims to combine the best of both worlds. To accomplish this, they employ a two-phase training approach that optimizes both the text embeddings and model weights.
During the initial phase, the focus is on refining the text embeddings (train the text encoder), while keeping the model (stable-diffusion) weights fixed. This optimization stage involves utilizing a high learning rate, which allows for the rapid exploration of potential embeddings that can serve as solid starting points for the subsequent phase.
In the following phase, the training process expands to encompass both the text encoders and the UNet of stable diffusion. By incorporating these elements, the model undergoes further refinement and fine-tuning.
Union-sampling
To address the challenge of generating images that combine multiple concepts, the researchers propose a technique called “union-sampling.” They observe that the model struggles to generate images that exhibit a combination of several concepts when each concept is considered separately during the training process. Therefore, they randomly select a subset of 𝑘 ≤ 𝑁 concepts and construct a text prompt as “a photo of [𝑣𝑖1] and . . . [𝑣𝑖𝑘],” as depicted in the figure above (1).
Notes: In this paper, [𝑣𝑖1] and . . . [𝑣𝑖𝑘] are referred to as “handles,” which essentially represent the subjects, objects, or concepts present in the image.
In order to address the challenge of generating images that combine multiple concepts, they propose a technique called “union-sampling”. They observe that the model struggles to generate images that exhibit a combination of several concepts when each concept is considered separately during the training process. Therefore, they randomly select a subset of 𝑘 ≤ 𝑁 concepts, and construct a text prompt “a photo of [𝑣𝑖1] and . . . [𝑣𝑖𝑘]” as depicted in figure above (1). Notes : [𝑣𝑖1] and . . . [𝑣𝑖𝑘] is known as “handles” in this paper, which basically mean the subject / object / concepts in the image.
Masked Diffusion Loss
The masked diffusion loss is an adaptation of the standard diffusion loss, wherein only the masked regions are considered for evaluating the loss. This means that the loss is calculated exclusively on the areas covered by the masks, ensuring that it captures the required concepts accurately.
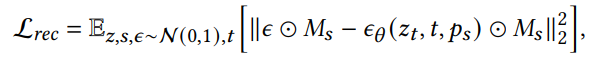 where 𝑧𝑡 is the noisy latent at time step 𝑡, 𝑝𝑠 is the text prompt, 𝑀𝑠 is the union of the corresponding masks, 𝜖 is the added noise, and, 𝜖𝜃 is the denoising network.
where 𝑧𝑡 is the noisy latent at time step 𝑡, 𝑝𝑠 is the text prompt, 𝑀𝑠 is the union of the corresponding masks, 𝜖 is the added noise, and, 𝜖𝜃 is the denoising network.
This loss encourages the model to faithfully reconstruct the concepts indicated by the masks. However, it does not provide a strict guarantee that each handle will be associated with a single concept only. For instance, when given a prompt like “a photo of [𝑣2] with the Eiffel Tower in the background,” the model may also generate [𝑣1], represented by the orange juice, alongside the intended concept.

Cross-attention loss
To address the limitation of the masked diffusion loss in ensuring that each handle is associated with a single concept, the researchers introduce an additional loss known as the cross-attention loss. This loss is formulated using a specific equation, as provided below:
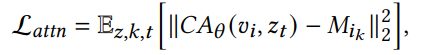 This loss is basically the difference in MSE between the cross-attention map and the input mask. The effect of cross-attention loss is obvious from the example given below:
This loss is basically the difference in MSE between the cross-attention map and the input mask. The effect of cross-attention loss is obvious from the example given below:
 The visualization of cross-attention heat map provided by the paper shows that the model tends to associate multiple concepts to a handles.
The visualization of cross-attention heat map provided by the paper shows that the model tends to associate multiple concepts to a handles.
Overall, the total loss is:
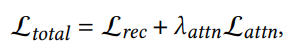 where 𝜆attn = 0.01 in their experiments.
where 𝜆attn = 0.01 in their experiments.
Results
To ensure a fair comparison with methods like TI or DB, which are trained on multiple images, the authors of this paper constructed a small collection of image-text pairs. They achieved this by randomly selecting a subset of tokens each time and creating a text prompt in the format of “A photo of [𝑣𝑥 ] and [𝑣𝑦 ] …”. The background was masked out using the provided masks, and a random solid background was applied. These curated image-text pairs were then used to train TI and DB models, as demonstrated in the following example:
 Specifically, they propose two automatic evaluation metrics for comparison:
Specifically, they propose two automatic evaluation metrics for comparison:
Prompt similarity: They use normalized CLIP embeddings to measures the degree of correspondence between the input text prompt and the generated image. (The cosine distance between embeddings of input text prompt and embeddings of generated image should be small if they are similar)
Identity similarity: To evaluate whether the generated image contains the same identity of the concepts, they compare the masked version of input image and output image and utilize the embeddings from DINO model.
The figure below shows the comparison results.
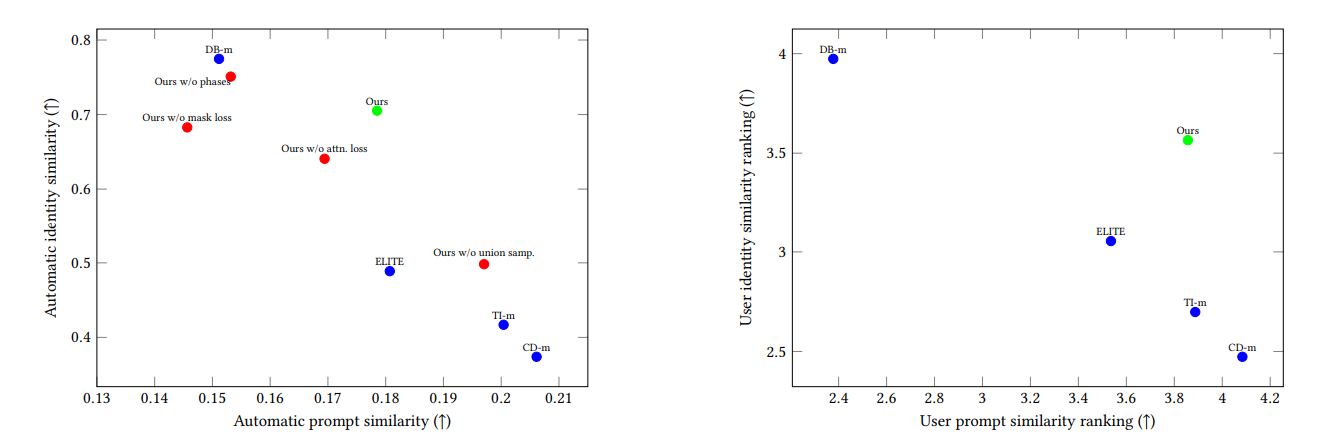 Left is the evaluation using automatic metrics and right is the human evaluation from survey collected using Amazon Mechanical Turk.
Left is the evaluation using automatic metrics and right is the human evaluation from survey collected using Amazon Mechanical Turk.
Applications
This is the most exciting part of the paper. With the ability of understand and disentangle the concepts from images, the potential application is limitless. Let’s present some of them here:
 We can generate variation of input images while preserving all the concepts!
We can generate variation of input images while preserving all the concepts!
 Your dog body is occluded? No problem!
Your dog body is occluded? No problem!
 Background is pretty? No worries, place your car (or even yourself) there!
Background is pretty? No worries, place your car (or even yourself) there!
 Whaaaat!?
While it is true that I am overreacting and the applications mentioned in the paper are not entirely new, the challenge of generating images that align with the user’s intended prompt remains significant. The ability of the model to comprehend the underlying concepts within images holds great potential. It can pave the way for more accurate and precise generations, as well as open up possibilities for applications beyond image generation. For instance, the model could be used to interactively modify the strength or presence of specific concepts in an image or enhance image-text modality retrievals etc.
Whaaaat!?
While it is true that I am overreacting and the applications mentioned in the paper are not entirely new, the challenge of generating images that align with the user’s intended prompt remains significant. The ability of the model to comprehend the underlying concepts within images holds great potential. It can pave the way for more accurate and precise generations, as well as open up possibilities for applications beyond image generation. For instance, the model could be used to interactively modify the strength or presence of specific concepts in an image or enhance image-text modality retrievals etc.
Limitations
- Inconsistent lighting: Since this method relies on a single image, it struggles to accurately represent concepts in different lighting conditions. For instance, if the image features objects captured in bright daylight, the generated results may exhibit similar lighting regardless of the given prompt, which can be problematic in scenarios with darker environments.
- Pose fixation: The model faces challenges when generating concepts with varying poses. Even when explicitly instructed to do so, it tends to produce images with similar poses, limiting the diversity of generated outputs.
- Limited concept learning capacity: The model may struggle to effectively learn and represent more than four concepts within an image. Beyond this threshold, the quality and coherence of the generated results may decrease.
- Significant computational demands: The process of extracting entities and fine-tuning the model incurs a substantial computational cost and requires a significant number of parameters. This can result in longer processing times, with approximately 4.5 minutes needed for concepts extraction and fine-tuning.
Conclusion
In conclusion, while this has some limitations, its breakthrough in disentangling and manipulating concepts within images holds immense potential for creative exploration and future advancements. With further studies in this direction, we can only imagine the transformative impact it will have on various fields. As the someone said, “Imagine what would happen with a few more papers down the road…”
Reference
Project Page
[1] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. An Image is Worth One Word: Personalizing Text-toImage Generation using Textual Inversion. arXiv:2208.01618 [cs.CV]
[2] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2022. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. arXiv:2208.12242 [cs.CV]
-
Previous
How to Craft a Website using Jekyll and GitHub Pages -
Next
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture