What is self-supervised learning?
Self-supervised learning, a learning paradigm passionately advocated by Meta AI’s VP and Chief AI Scientist, Yann LeCun, provides a remarkable avenue for models to acquire meaningful representations directly from unlabeled data. This paradigm offers a promising solution to the high cost and labor-intensive nature of annotated data, as models can leverage the abundant unlabeled data that exists in various domains. While self-supervised learning has gained significant traction in recent years, it is not an entirely new approach to training models. Some popular model trained using self-supervised approach are BERT, GPT, ELECTRA in natural language processing and SimCLR, DINO, self-supervised ViT in computer vision. Specifically, there are two widely used approach for self-supervised learning: (While our focus will be on self-supervised learning in computer vision, it’s important to note that similar principles are applied across various fields.) Invariance-based methods : These methods focus on augmenting the input images and optimizing the encoder model to produce similar embeddings for both the augmented and original images. Generative methods : These methods involve removing a portion of the input image and training the model to predict the missing part.
What are the limitations of current self-supervised approach?
Challenges with invariance-based methods
Invariance-based methods commonly rely on hand-crafted augmentations, including random scaling, cropping, and color jittering, to generate diverse views of images. The aim is to optimize the model to produce similar embeddings for images with different views. However, this approach introduces certain challenges and biases that can impact the model’s performance on downstream tasks. One such issue arises from the strong biases introduced by these augmentations, which may influence the model’s understanding of the underlying content. For instance, in image classification tasks, the model may require a holistic understanding of the image’s overall content (high-level abstraction) to make accurate categorical decisions. On the other hand, in image segmentation tasks, the model should focus on capturing finer-level details, such as object boundaries, to assign separate segmentations. Additionally, these augmentations are specifically tailored for images and may not readily generalize to other modalities, such as audio data.
Challenges with generative methods
Generative methods, in comparison to view-invariance approaches, require less prior knowledge and offer greater generalizability across different modalities beyond just images. However, certain challenges have been identified when employing generative methods. Research indicates that these methods often necessitate extensive fine-tuning to achieve comparable performance with invariance-based approaches. Moreover, they tend to underperform in off-the-shelf evaluations, such as linear probing, where the entire weights of the model are frozen, and only the last classifier layers are trained.
Introducing I-JEPA: Image-based Joint Embedding Predictive Architecture
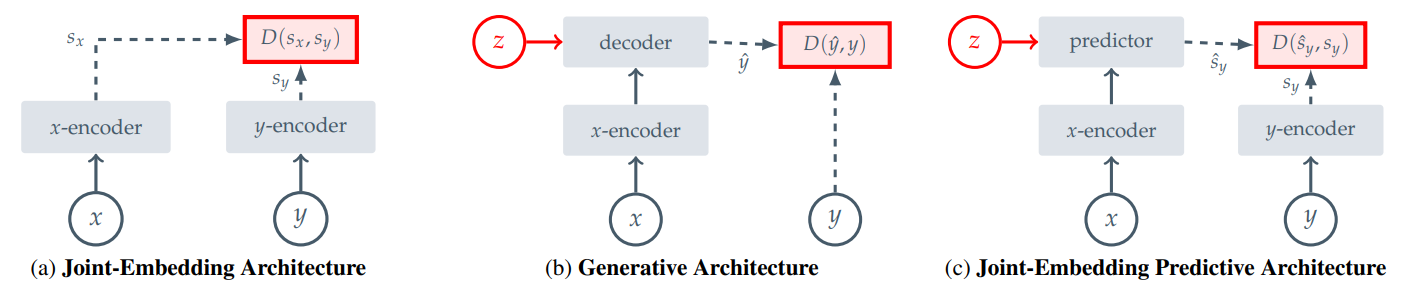 To address the aforementioned challenges, Meta AI has proposed an innovative learning architecture called Image-based Joint Embedding Predictive Architecture (I-JEPA). At first glance, it may seem similar to generative architectures, but I-JEPA distinguishes itself by applying the loss function in the embedding space rather than the pixel space. This strategic difference enables the model to focus on learning semantic features rather than pixel-level details that may not be directly relevant to the target task. By optimizing the model to extract meaningful representations from the embedding space, I-JEPA aims to enhance the model’s ability to capture higher-level concepts and improve overall performance on downstream tasks.
To address the aforementioned challenges, Meta AI has proposed an innovative learning architecture called Image-based Joint Embedding Predictive Architecture (I-JEPA). At first glance, it may seem similar to generative architectures, but I-JEPA distinguishes itself by applying the loss function in the embedding space rather than the pixel space. This strategic difference enables the model to focus on learning semantic features rather than pixel-level details that may not be directly relevant to the target task. By optimizing the model to extract meaningful representations from the embedding space, I-JEPA aims to enhance the model’s ability to capture higher-level concepts and improve overall performance on downstream tasks.
Note: I-JEPA does not requires any hand-craft augmentations
Below is a diagram illustrating the underlying mechanism of I-JEPA:
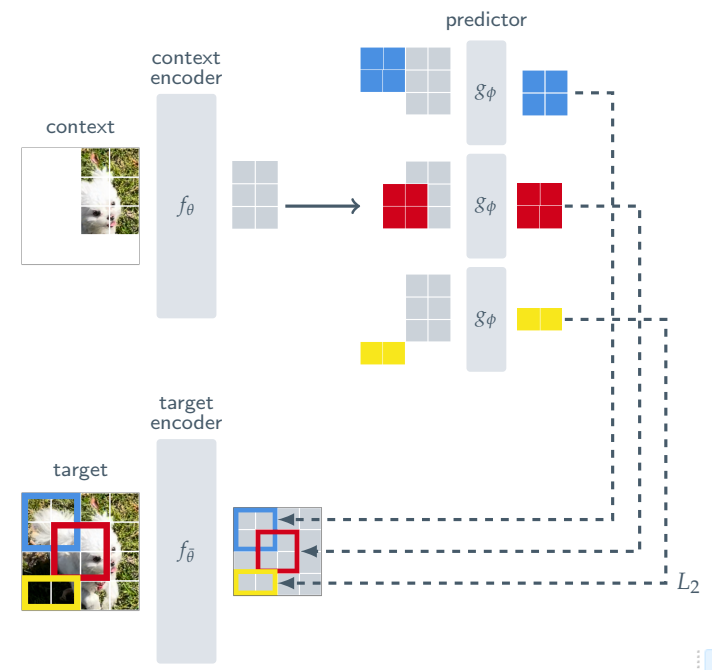 The core idea of I-JEPA is to predict the representations of various target blocks given a context block. The architecture consists of three key components: the context encoder, target encoder, and a predictor, all of which are based on vision transformers ViT
The core idea of I-JEPA is to predict the representations of various target blocks given a context block. The architecture consists of three key components: the context encoder, target encoder, and a predictor, all of which are based on vision transformers ViT
Note: While the architecture of I-JEPA may resemble that of masked-autoencoders (MAE), there is a significant distinction between the two. In MAE, a decoder is utilized to reconstruct the representation back into the pixel space for loss calculation. In contrast, I-JEPA employs a predictor that operates within the representation space to make predictions. This key difference allows I-JEPA to focus on predicting representations directly, without the need to decode them back into the pixel space.
How they select the context block?
In I-JEPA, the selection of the context block plays a crucial role in training the model to predict the representations of various target blocks. The process begins by sampling a single block, denoted as x, from the image. To introduce variability, the context block is randomly scaled within the range of 0.85 to 1.0, while maintaining a unit aspect ratio. To prevent any information leakage between the context block and the target block, any overlapping region between them is removed.
But how the target block are generated?
To generate target blocks in I-JEPA, the input image y is converted into a sequence of non-overlapping patches. These patches are then fed into the target encoder to obtain the corresponding patch-level representations. Once the patch-level representations are obtained, M blocks are randomly sampled (might be overlapping) for loss computation. It’s important to note that the target blocks are derived from the output of the target encoder, which consists of representations, rather than directly from the input image. This ensures that the model focuses on the learned representations when computing the loss, promoting the optimization of meaningful semantic features rather than pixel-level details.
It’s time for prediction
The prediction process in I-JEPA is straightforward yet effective. It involves taking the output of the context encoder and using a mask token for each patch that needs to be predicted. The model then generates patch-level predictions for the various target blocks. The mask tokens are parameterized by a shared learnable vector, which is enhanced with positional embeddings to capture spatial information. In essence, this process is repeated M times, corresponding to the number of target blocks, ensuring that predictions are made for each specific block.
Loss: The loss is simply the average L2 distance between the predicted patch-level representations and the target patch-level representation.
Why it works?
In I-JEPA, the key objective is to predict the representations of various target blocks based on the context representation. For this prediction process to be successful, it is crucial that the context representation contains sufficient information and is informative enough for the predictor to generate accurate predictions for the target blocks. In other words, the encoder must be optimized to generate strong representations.
The parameters of the predictor and context encoder are learned through gradient-based optimization, while the parameters of the target encoder are updated via an exponential moving average (EMA) of the context-encoder parameters due to its previous success.
Results
One crucial aspect that I focused on while reading this paper was whether the increase in performance came at the expense of efficiency. However, the results of this approach demonstrate that it achieves a remarkable balance between scalability and accuracy, surpassing previous methods in terms of scalability.
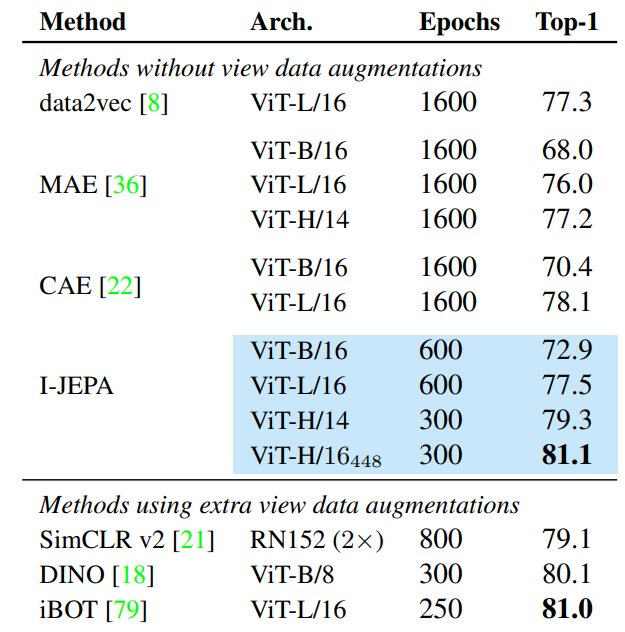
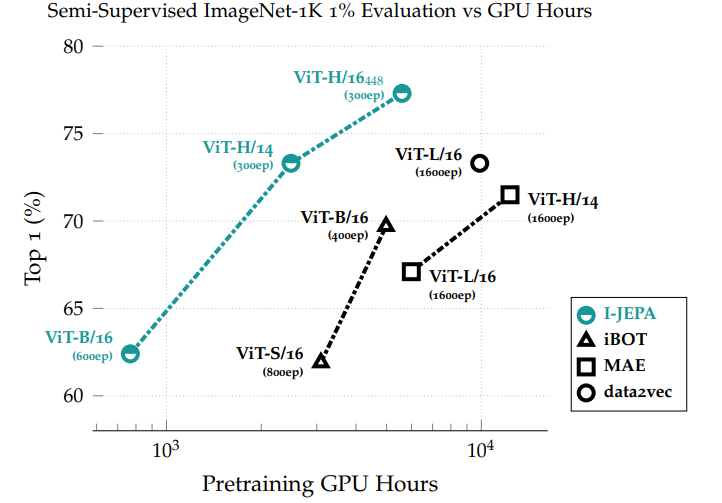 Below is the result of Linear-evaluation on ImageNet-1k.
Below is the result of Linear-evaluation on ImageNet-1k.
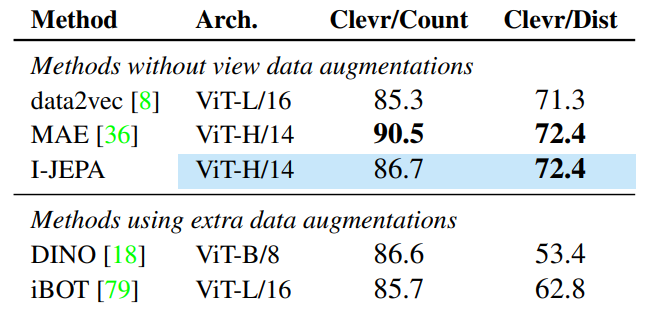
 Result on other task such as object counting and depth prediction to proves its effectiveness in effectively captures low-level image features during pretraining.
Result on other task such as object counting and depth prediction to proves its effectiveness in effectively captures low-level image features during pretraining.
 “Comparison between applying loss in pixel-space versus representation space.”
“Comparison between applying loss in pixel-space versus representation space.”

Conclusion
In conclusion, this paper introduces a straightforward yet effective approach to learn semantic information without the need for manual data augmentations. The concept of prediction in the representation space is demonstrated, showcasing its superiority over pixel-space prediction, as the latter tends to capture finer pixel-level details that may introduce irrelevant information to the models. Notably, the scalability of this approach is particularly impressive, requiring less computational resources compared to previous methods while achieving state-of-the-art performance.
-
Previous
Break-A-Scene: Extracting Multiple Concepts from a Single Image -
Next
FlashAttention: Fast and Memory Efficient Exact Attention with IO Awareness